
Most services can be operated by complex distributed networks. Mission-critical systems include banking systems, security systems, and healthcare systems that track patient health. Downtime or unavailability costs money and may even endanger lives.
These mechanisms need to be watched over. To maintain systems operating with as little interruption as possible, many metrics are helpful. The Mean Time To Recovery is one of them (MTTR).
It's simple to presume that MTTR is a single measure with a single meaning when we discuss it. But in reality, it might signify four distinct dimensions. While the four measures do overlap, the R can represent repair, recovery, react, or resolve, and each has its own significance and nuances.
Therefore, it's a good idea to explain which MTTR your team means and how they're defining it if they're talking about monitoring MTTR. Your team needs to be in agreement about precisely what you're monitoring before you start keeping track of triumphs and mistakes. Make sure everyone is talking about the same thing.
- What is Mean Time to Recovery (MTTR)?
- MTTR as measurement
- How do you measure MTTR?
- Ways to improve the performance of MTTR
- Limitations of MTTR
What is Mean Time to Recovery (MTTR)?
Mean Time to Recovery, or MTTR, is a word used in software to describe how long it takes for a service to go from being identified as "down" to be "available" from the viewpoint of the user. The financial effect on the business can then be calculated using this measurement.
Repair, Recover, and Resolve are three possible meanings for the "R" in MTTR. We'll describe recovery as bringing service from a "down" state to an "available" state, and we'll discuss it from the customers' point of view.
In manufacturing, "Mean Time To" is a common gauge of the typical time interval between two occurrences. The mean time it takes for a service to be restored after a failure has been discovered is known as the mean time to recovery.
#1 Mean Time To Repair
The mean time to repair, or MTTR, is the length of time it typically takes to fix a device (usually technical or mechanical). Both the fixed time and any trial time are included. The timer on this metric doesn't end until the system is completely operational once more.
By totaling the time spent on repairs over the course of a particular timeframe and dividing it by the number of repairs, you can determine MTTR.
Therefore, suppose we are considering fixes over the span of a week. Ten failures occurred during that period, and systems required active maintenance for four hours. 240 minutes make up an hour. split by 10, 240 equals 24. which indicates that the average fix period in this scenario would be 24 minutes.
#2 Mean Time to Recovery
The average amount of time needed to recoup from a system or product breakdown is called the mean time to recovery (MTTR). This spans the entire period of the failure, from the moment the system or product malfunctions until it resumes normal operation in its entirety.
According to DevOps Research and Assessment, it's a crucial DevOps indicator that can be used to assess the reliability of a DevOps team (DORA).
By adding up all the outages during a given time frame and splitting it by the number of occurrences, the mean time to recovery is determined. Let's assume that over the course of a day, two distinct events caused our systems to go down for 30 minutes each. Therefore, our MTTR is 15 minutes when 30 is split by 2.
#3 Mean Time To Resolve
The usual amount of time needed to completely fix a mistake is called the MTTR (mean time to resolve). This involves the time needed to identify the failure, identify the issue, and fix it, as well as the time needed to make sure the failure won't occur again.
This measure increases the team's accountability for long-term performance improvement. It's the distinction between extinguishing a fire and then insulating your home against future fires.
This MTTR and client happiness are strongly correlated, so it's important to take notice of it.
Here's an illustration: Say a system experiences 18 failures over the course of 90 days. The Time to Recovery for each individual failure is the amount of time between the outage's discovery and resolution.
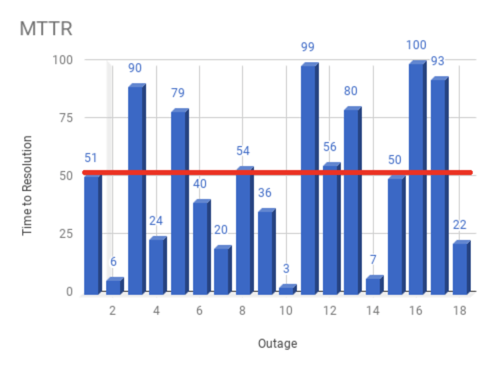
This graph shows 18 distinct failures. From the time a failure is first noticed to the time the service is restored, each disruption has a specific time frame. The term "recovered" here alludes to the user's experience. If customers can access the server, it has recovered. The MTTR for this 90-day span is 51 minutes because 51 minutes is the mean, or average, duration between detection and recovery.
We will see how to measure MTTR in detail and various ways to improve its performance.
MTTR as Measurement
Monitoring is the practice of measuring various metrics such as response rates, errors, and queries per second in mission-critical systems to ensure prompt response to performance issues and complete failures. These metrics provide valuable insights for teams to enhance efficiency and reliability. One important metric used to gauge system uptime and support agreements like Service Level Agreements (SLAs) is the Mean Time to Repair (MTTR).
SLAs are contractual agreements between internal teams or between a service provider and a customer. However, SLAs can only be enforced when the availability of the system is measured. If availability is not measured, it cannot be improved upon.
MTTR refers to the average time taken to repair a device, typically of a technical or mechanical nature. It includes both the actual time spent on fixing the issue and any required testing time. The measurement of MTTR continues until the system is fully operational once again.
MTTR also encompasses the time needed to identify the failure, diagnose the issue, implement the fix, and ensure that the failure does not recur. This metric emphasizes the team's responsibility for long-term performance improvement. It signifies the difference between simply extinguishing a fire and taking proactive measures to prevent future fires.
It is crucial to recognize that MTTR and customer satisfaction are strongly correlated. Therefore, paying attention to MTTR is essential for maintaining high levels of customer happiness and confidence in the system or service provided.
How do you calculate MTTR?
MTTR is commonly used in various industries to assess the efficiency of maintenance and repair processes.
The formula to calculate MTTR is as follows:
MTTR = Total Repair Time / Number of Failures

Here's an example to illustrate how to calculate MTTR in real-time:
Let's consider a manufacturing company that operates a machine. Over a period of one month, the machine experienced three breakdowns. The repair times for each breakdown were as follows:
Breakdown 1: 2 hours Breakdown 2: 4 hours Breakdown 3: 3 hours
To calculate the MTTR, we sum up the total repair time and divide it by the number of failures:
Total Repair Time = 2 hours + 4 hours + 3 hours = 9 hours Number of Failures = 3
MTTR = 9 hours / 3 = 3 hours
In this example, the Mean Time to Repair (MTTR) for the machine is calculated as 3 hours. It means that, on average, it takes 3 hours to repair the machine after a breakdown occurs.
How do you Measure MTTR?
Upon discovery of an issue, a ticket is created to document the problem. This can be done manually by individuals or automatically through monitoring systems. The ticket serves as a formal record of the incident and serves as the trigger for initiating the MTTR measurement.
The clock for measuring MTTR starts ticking as soon as the first note or record of the issue is made in the ticketing system. This serves as the starting point for tracking the time taken to resolve the problem.
Once the problem is successfully resolved, the clock stops. This occurs when the resolution is accurately documented within the same ticketing system used for reporting the incident. It is crucial to ensure that the resolution is recorded properly to maintain the integrity of MTTR reporting.
To effectively track MTTR, it is essential to establish a clear reporting strategy for service recovery. Consistent recording of service restoration in the ticketing system is necessary to maintain accuracy in MTTR reporting. Following routine administrative procedures can help ensure that the impacted service(s) have been fully restored before closing the tickets.
To measure MTTR (Mean Time to Repair) accurately, the following technical steps can be followed
- Initiation: The MTTR measurement begins when errors or failures are discovered in the system or component. This typically occurs when the problem is reported through IT service management tools or when monitoring programs generate incident tickets.
- Ticket Creation: A ticket is created to document the reported problem. This can be done manually by individuals or automatically through monitoring systems. The ticket serves as a record of the incident and triggers the start of the MTTR measurement.
- Clock Start: The clock for MTTR starts as soon as the first note or record of the issue is made in the ticketing system. This marks the beginning of the time measurement for resolving the problem.
- Service Recovery: Once the problem is resolved, the clock stops. This occurs when the resolution is documented in the same ticketing system used for reporting the incident. It is important to ensure that the resolution is accurately recorded within the system to maintain the integrity of MTTR reporting.
- Reporting Strategy: To effectively track MTTR, it is crucial to have a clear reporting strategy for service recovery. If service restoration is not consistently recorded in the ticketing system, the accuracy of MTTR reporting may be compromised. It is recommended to follow routine administrative procedures to ensure that the impacted service(s) have indeed been restored before closing the tickets.
- Customization: Many IT service management tools offer customization options. If ticket closure is not considered the appropriate "clock-stopping" event for calculating the outage length, you can modify the system. Consider adding a "time-resolved" category to accurately capture the end time of the downtime. Operations personnel can use this "time-resolved" field as the end time and the "ticket open time" as the start time and conclusion of the downtime.
- Training and Awareness: It is crucial to educate and inform operations staff about the importance of tracking MTTR and the proper procedures for stopping the clock on complaints once service is resumed. By following these instructions, operations staff can ensure the accurate measurement and reporting of MTTR using the ITSM system.
Ways to Improve the Performance of MTTR
Improving MTTR requires a systematic approach and the implementation of various strategies. Here are several ways to enhance MTTR performance:
- Incident Management Process: Establish a well-defined incident management process that outlines the steps to be taken from the initial identification of an issue to its resolution. This process should include clear roles and responsibilities, escalation procedures, and a streamlined workflow to minimize delays and ensure prompt resolution.
- Monitoring and Alerting: Implement robust monitoring and alerting systems to proactively detect and notify relevant teams about issues or potential problems. This allows for quicker response times and minimizes the time between identifying an incident and initiating the repair process.
- Automated Remediation: Leverage automation tools and scripts to enable automatic remediation for known issues or common problems. By automating certain tasks, you can reduce human error and significantly speed up the time it takes to fix recurring issues.
- Knowledge Base and Documentation: Maintain a comprehensive knowledge base and documentation repository that includes troubleshooting guides, known issues, and resolutions. This enables support teams to access relevant information quickly and efficiently, accelerating the troubleshooting and resolution process.
- Collaboration and Communication: Foster effective collaboration and communication among different teams involved in incident response. Encourage open lines of communication, implement incident management tools or platforms for real-time collaboration, and establish clear communication channels to ensure prompt and accurate information exchange.
- Skill and Knowledge Development: Invest in training and development programs to enhance the skills and knowledge of support teams. Equipping them with the necessary expertise and resources will enable them to diagnose and resolve issues more efficiently, thereby reducing MTTR.
- Continuous Improvement: Regularly analyze incidents and post-incident reviews to identify patterns, trends, and areas for improvement. Implement a feedback loop to learn from past incidents and apply lessons learned to prevent similar issues in the future. Continuously refining processes based on insights gained from these reviews will lead to faster resolution times.
- Incident Prioritization: Establish a prioritization framework that classifies incidents based on their impact and urgency. This allows teams to allocate resources and focus on resolving critical incidents promptly, thereby reducing the overall MTTR.
- Performance Metrics and Analysis: Track and analyze performance metrics related to incident management, including MTTR. Use these metrics to identify bottlenecks, areas of improvement, and trends. Regularly review and assess the data to drive continuous optimization efforts.
- System Redundancy and Resilience: Design and implement systems with built-in redundancy and resilience to minimize the impact of incidents and enable faster recovery. This could include redundant hardware, failover mechanisms, load balancing, and disaster recovery plans.
Limitations of MTTR
MTTR provides a high-level measure of how quickly an issue can be fully resolved, but it may not provide sufficient information to identify specific areas of improvement within the workflow. For instance, if the MTTR is longer than expected, it is essential to investigate where in the process delays are occurring and what factors contribute to the extended response time.
One potential source of delay could be the notification system. Are there delays between the occurrence of an issue and the generation of a notification? Are notifications taking longer than necessary to reach the intended recipients? Analyzing the efficiency of the notification mechanism can help identify potential bottlenecks in the incident response process.

Another aspect to consider is the effectiveness of diagnostics. Are there efficient methods in place to identify and diagnose issues accurately? Are there opportunities to enhance diagnostic procedures to expedite the identification of problems?
Additionally, the effectiveness of the resolution process should be evaluated. Are the repair staff adequately skilled and equipped to address the issues efficiently? If the majority of the time is consumed by the repair process, it is crucial to investigate potential barriers or inefficiencies that hinder the repair staff's performance.
While MTTR can serve as an initial indicator of potential issues in the recovery process, it should not be relied upon as the sole metric for assessing the overall effectiveness of incident response. To gain a comprehensive understanding of the underlying factors impacting MTTR, a deeper analysis is necessary.
This may involve examining detailed metrics, conducting root cause analysis, and investigating the specific steps involved in incident resolution to identify opportunities for improvement and enhance the overall efficiency of the recovery process.
Conclusion
That which cannot be quantified cannot be improved. Mean Time To Recovery gauges a system's availability, allowing an organization to pledge to certain levels of availability.
These agreements, known as Service Level Agreements, may be formed with external customers or between departments within an organization. The first stage in enhancing MTTR is measurement. Operational procedures like postmortems will aid in lowering MTTR by decreasing individual failure recovery periods.
In the meantime, recovery reveals how rapidly you can restart your systems. You can determine how much of the recovery time goes to the team and how much is due to your warning system by layering in the meantime to react. You can begin to see how much time the team is spending on fixes as opposed to diagnosis by adding more layers of mean time to repair.
You can begin to comprehend the full extent of fixing and addressing problems beyond the real downtime they cause by adding mean time to resolve the equation.
Remember that MTTR is typically computed using business hours, so if you recoup from a problem at closing time one day and work to solve the root cause the following morning, those 16 hours would not be included in your MTTR. It's crucial to decide how you will monitor time for this metric if you have teams spread across several locations working around the clock or if you have on-call workers working after hours.
ReplayBird - Driving Revenue and Growth through Actionable Product Insights
ReplayBird is a digital experience analytics platform that offers a comprehensive real-time insights which goes beyond the limitations of traditional web analytics with features such as product analytics, session replay, error tracking, funnel, and path analysis.
With Replaybird, you can capture a complete picture of user behavior, understand their pain points, and improve the overall end-user experience. Session replay feature allows you to watch user sessions in real-time, so you can understand their actions, identify issues and quickly take corrective actions. Error analysis feature helps you identify and resolve javascript errors as they occur, minimizing the negative impact on user experience.
With product analytics feature, you can get deeper insights into how users are interacting with your product and identify opportunities to improve. Drive understanding, action, and trust, leading to improved customer experiences and driving business revenue growth.
Try ReplayBird 14-days free trial
Further Reading:
 Uma
Uma Velantina
Velantina Uma
Uma

{kind=link}